During the past decade, there has been a revolution in search technology that has deep implications for any business with a web presence. That revolution centres around semantics – the meaning behind words, or Schema Markup and Structured Data.
This article will look at the background of search and how semantics have become important; the tools at our disposal to help index a site’s content semantically; a brief introduction to the practical side of this with supporting links; and an exploration of some of the fundamental concepts underpinning this – entities and trust. Finally, we’ll look at what is on offer as far as search results go and what the end-user might see.
- A brief history of search and search technology
- The problem with Keywords without a context and the importance of disambiguation
- Machine-readable semantic languages
- Schema.org – providing a universal semantic language for search engines
- Example of Schema Markup in JSON-LD
- Nodes, Entities, and the knowledge graph
- Reflections in SERP’s – Rich Cards, Rich Snippets, and other human accessibility layers.
- Conclusion
1. A Brief History of Search and Search Technology
The nature of online search technology has changed quite considerably since its birth in 1990. Once they had evolved a bit, from 1995 onwards, search engines worked by providing a list of possible answers to search queries. This was based on the words they contained in the search query, and it was then left to the searcher to select what looked like the best match to show them what they were searching for. This ambiguity and transparency in the search engine algorithms meant that you could use many tricks to gain high positions in the search results without necessarily containing the information that the search query was trying to find. Or in other words – search results were often not very useful to the searcher, and there was a lot of “spam”, so to speak.
Early search engines like Lycos, Yahoo, WebCrawler, Excite, AltaVista and Infoseek all made contributions to how end-users could navigate and find things on the World Wide Web (“WWW”). But they all struggled to stay ahead of those seeking to game the systems. Natural language queries, methods of indexing, the crawling of meta-data, back-links – these were a few of the innovations that gave search engines far greater scope. However, it also opened them up to being “gamed” and subjected to “Black Hat” techniques, which perhaps ironically gave rise to the vast majority of the SEO industry 15 years ago.
Google made a lot of effort to try and put this underhand activity firmly in the past, and it put restrictions in place to stop spam with the introduction of “nofollow” links in 2005. The Panda update in 2011 also put the squeeze on using techniques like content farms and scraper sites – all popular underhand ways to try and get those precious top page rankings. During this time, search engines that had become dominant – Google, Yahoo! And MSN – collaborated to develop Schema.org, a key development for realising a semantic web. The search engines designed schema to provide a fundamental lexicon of terms that would be useful for describing websites and the activities that go on around them.
The Google Hummingbird algorithm in 2013 was designed to make semantics central, and it was at this point Google started to reward websites incorporating semantic markup and Schema. Context and meaning started to become a reality in an internet search. The aim: to make search return accurate and relevant information for the end-user. Since 2013 AI and semantics have become the heart of search engine technology, and user experience has become absolutely central. As recently as 2017, a Google search algorithm update unofficially dubbed “Fred” punishes sites with low-quality backlinks and sites that prioritise monetisation over user experience. These days websites have to do what they say on the tin and mean what they say. Also, speed, ease of use and clarity are crucial factors in getting listed in search results.
2. The Problem with Keywords without a Context and the Importance of Disambiguation
Even those who only have a passing interest in internet technologies are probably aware that the words associated with a web page are important. As with any index, keywords are used to match the search with the most relevant results when trying to find something in a mass of information. However, searches based purely on keywords – strings of text – don’t consider ambiguity, synonyms, etc. Before Hummingbird, searches on Google were not particularly accurate and required some digging around to find exactly what you were looking for. Inevitably, competition for certain keywords became very high, especially when the “real estate” of the Search Engine Results Pages (“SERP”) is effectively just the first 3 or 4 positions, and the whole industry was born to take advantage of searches based entirely on keywords.
The problem was both the ambiguity of meaning and the ambiguity of identity. To illustrate the issue, here’s an example from the Wikipedia page on “Word-sense Disambiguation”:
“To give a hint of how all this works, consider three examples of the distinct senses that exist for the (written) word “bass“:
- a type of fish
- tones of low frequency
- a type of instrument
and the sentences:
- I went fishing for some sea bass.
- The bass line of the song is too weak.
To a human, it is obvious that the first sentence is using the word “bass (fish)”, as in the first sense above, and that in the second sentence, the word “bass (instrument)” is being used as in the latter sense. Developing algorithms to replicate this human ability can often be a difficult task, as is further exemplified by the implicit equivocation between “bass (sound)” and “bass (instrument)”.
While machines can manipulate pure data at incredible speeds, the measure of context is a recent development. Semantics – the differences and/or similarities in perceived meanings of words, sentences, and/or phrases relative to context – is now a factor in the machine algorithms running search engines. And so there has been a lot of effort made by Google to make it clear and easy for those submitting websites and pages that they need to make their content understandable to these machine algorithms and specify the meaning of their web pages with a high degree of accuracy.
The vocabulary used by web pages needs to be authentic. It used to be enough to include certain words in the text of pages to rank for them, but no more! Google’s artificial intelligence algorithm (RankBrain) detects patterns of search queries, their context and consequent user behaviour. This has resulted in the focus shifting very strongly towards providing a good user experience and useful information. The real advantage is now in content with a clear context solidified around trust. Ambiguity is no longer useful, and as a result, confusing and unengaging content is irrelevant. Google is now giving major boosts to quality content. Why? The end-user, the searcher. From their behaviour, Google can now tell if the search results gave a meaningful answer to what they were looking for.
In the early days of the search engines, a large percentage of the vetting of site submissions used to be done “by hand” to give search results some accuracy. However, the scale of growth in the WWW and the number of pages and sites to be tracked became too much for that technique (though it is still used to calibrate search accuracy, apparently). A machine algorithm became essential and, by default, a language for it. And thus, we have…
3. Machine Readable Semantic Languages
3.1 Schema.org – Providing a Universal Semantic Language for Search Engines
In 2011, the major search engines collaborated to lay down a vocabulary and language so that machines could read content made available on the internet. The result was the Schema ontological framework – a vocabulary to be used in conjunction with a certain type of markup that makes the content of a web page explicit in the metadata. Since then, JSON-LD has steadily been gaining ground as the preferred markup method over RDFa or Microdata. A quick look at the entire Schema hierarchy should give you some idea of its scope.
The vocabulary is made up of URI’s – stable nodes in the web that are used as atomic or basic statements in the language.
“A Uniform Resource Identifier (URI) is a string of characters designed for unambiguous identification of resources and extensibility via the URI scheme.” – Wikipedia https://en.wikipedia.org/wiki/URI
For example, to identify the nature of your business unambiguously, you might use the URI http://schema.org/HealthAndBeautyBusiness or the more general http://schema.org/LocalBusiness. While Schema.org sets a fundamental set of terms, you can add other ontologies. For example, auto.schema.org adds specific terms for cars, motorcycles, etc. Similarly, Wikipedia can be used as a stable reference possessing unique addresses for concepts and things. Because Wikipedia is such a well-established and trusted entity, its pages can also be used as part of the ontological language.
Schema.org provides a universal semantic language for those wanting to markup their identity and content with machine-readable data. Since it is based on RDF, it can also be linked to many other ontologies with their own URI’s for particular terms. The data that it holds can then be interpreted and linked to other semantic statements.
“Uniform Resource Identifiers (URI) are a single global identification system used on the World Wide Web, similar to telephone numbers in a public switched telephone network. URIs are a key technology to support Linked Data by offering a generic mechanism to identify entities (‘Things’) or concepts in the world.” – Australian Government Linked Data Working Group
3.2 Example of Schema Markup in JSON-LD
A semantic statement would be a “triple”, made up of stable URI’s. For example, we could state in semantic terms:
[http://schema.org/LocalBusiness] [http://schema.org/Service] [https://en.wikipedia.org/wiki/Digital_marketing]
That is: This Local Business provides the Service Digital Marketing.
Using the Schema Ontology and JSON-LD markup, this would look something like this:
{
“@context”: “http://schema.org”,
“@type”: “LocalBusiness”,
“makesOffer”:
{
“@type”: “Offer”,
“itemOffered”:
{
“@type”: “Service”,
“name”: “Digital Marketing”,
“sameAs”: “https://en.wikipedia.org/wiki/Digital_marketing”
}
}
}
This is a very brief and rudimentary example of implementing Schema with JSON-LD. There is so much detail in the Schema vocabulary that it quickly becomes overwhelming. Also, be warned that some of the documentation and examples on the site are incomplete and/or confusing. It seems that the best way of using it is still being hashed out. However, the main pages on the site are definitely worth digesting.
When trying to tackle Schema to markup your website, you should also bear in mind that there are only so many things that have been implemented from it in the search engines. So, to begin with, it’s probably worth sticking to the examples given in Google’s Search Gallery. For further examples and information on the writing JSON-LD markup, check out some of the following sites:
- How to write great Schema Markup for your company
- How to add structured data to your website
- JSON-LD playground
- Schema Markup JSON-LD Generator
- Steal Our JSON-LD
4. Nodes, Entities, and the Knowledge Graph
“Things, not strings”
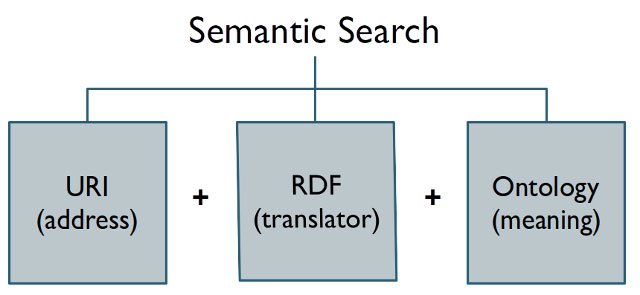
Illustration 1: The fundamental requirements for Semantic Search, courtesy of David Amerland
Entities in the semantic web are trusted points around which other data revolves. An entities address – how to reference and link to it – is its URI. http://www.schema.org is the base URI used for all the vocabulary of Schema. Companies and businesses could establish their entity by specifying a URI with a website and including semantic statements to that effect.
By embracing semantics, the nature of search on the internet has changed from a system that you could easily fool into a larger conversation where authority, trust, reputation and influence are integral to the stability of the node and where it sits in the overall landscape. Thus, websites representing businesses and companies must be consistent, useful, reliable, and easy to access.
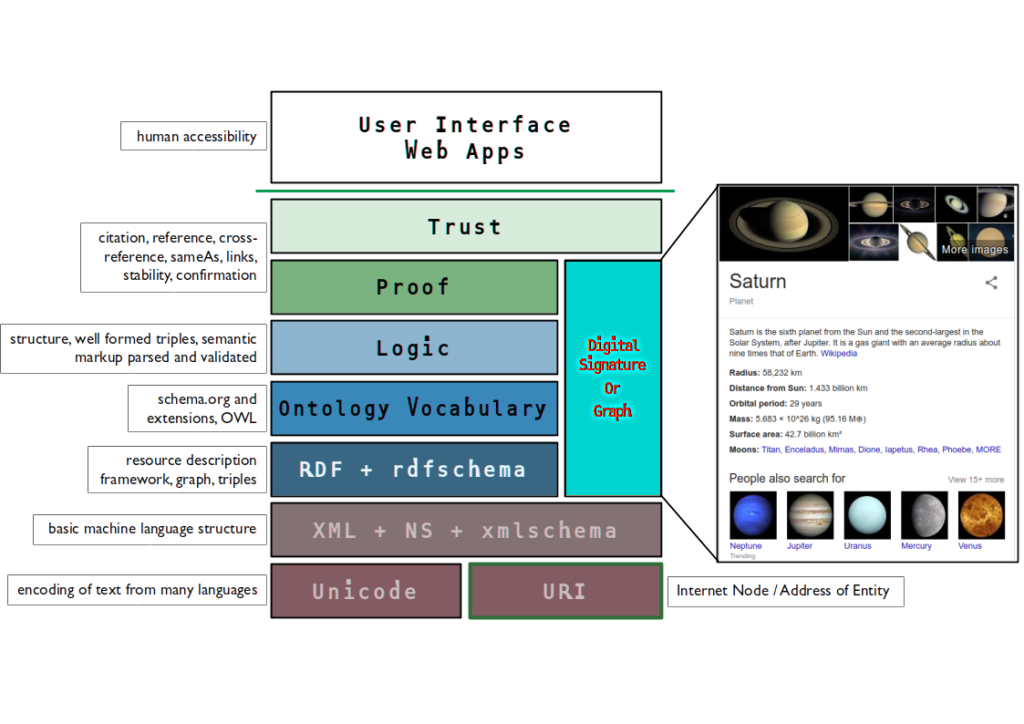
Illustration 2: The Semantic Web Tower, first proposed by Tim Berners-Lee, with annotation.
An entity could have many semantic statements attached to its node or URI. This describes its identity in certain terms that are machine-readable. Relationships with the Entity can be stated, determined, and found. The language used to describe a business becomes central. Straplines, key concepts, themes, and identity could and should all point to URI’s to strengthen their place in the WWW and help form a clear picture of the business’s presence online. The sum of these forms the Digital Signature, and this is, to some extent, what is visualised in the Knowledge Graph on Google. Associated images, facts, data and so on can be drawn from all over the Web to populate this.
Back in 2006, Tim Berners-Lee described linked data as follows:
“The Semantic Web isn’t just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data.”
And that is largely what Google’s Knowledge Graph is intended to consolidate so that answers to user questions and queries can be displayed in one place directly on Google.
Here is an excellent example of some of these concepts being applied by Connecting Data: London as a Graph – make sure to check out the Schema in Google’s Structured Data Testing Tool. More recently, Google Search Console (formerly Webmaster tools) has introduced a new reporting section for unparsable structured data. Should you implement any Schema on your website, GSC will flag any errors or opportunities for improvement in this report.
Semantic statements are held by the quality and authority of their references (i.e. the URI’s). The entity described by these statements takes its place in a wider conversation of context and meaning. For some idea of the extent of what these mean, have a look at http://lod-cloud.net/clouds/lod-cloud.svg – the LOD cloud is a visualisation of the extent of the Semantic Web and its many data silos, nodes and vocabularies.
 Illustration 3: Can you spot your business entity? Find a place in the conversation. (Source: bordalierinstitute.com)
Illustration 3: Can you spot your business entity? Find a place in the conversation. (Source: bordalierinstitute.com)
5. Reflections in SERP’s
Comparison of Google’s SERP’s between 2011 and 2018: Rich Cards, Rich Snippets and Other Human Accessibility Layers
The below two screenshots give you some idea of the changes that have taken place in Google’s Search Result Pages since the introduction of the Knowledge Graph. The main thing to note is that the “10 blue links” have been slowly breaking up and various “Cards” and “Rich Snippets” now sit amongst the search results. In terms of SERP’s, this is the payoff for implementing Schema markup on your site. In terms of the Semantic Web Tower illustrated earlier, this is the top-level – the human access –, and it is a sign of things to come.
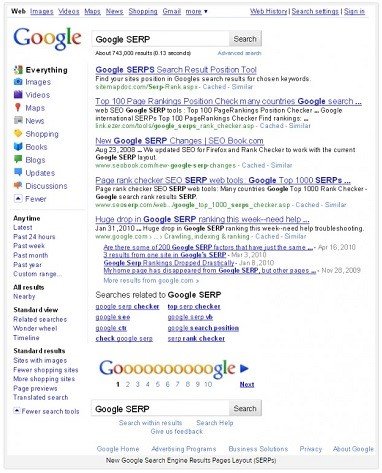
Illustration 4: Google SERP’s c.2011
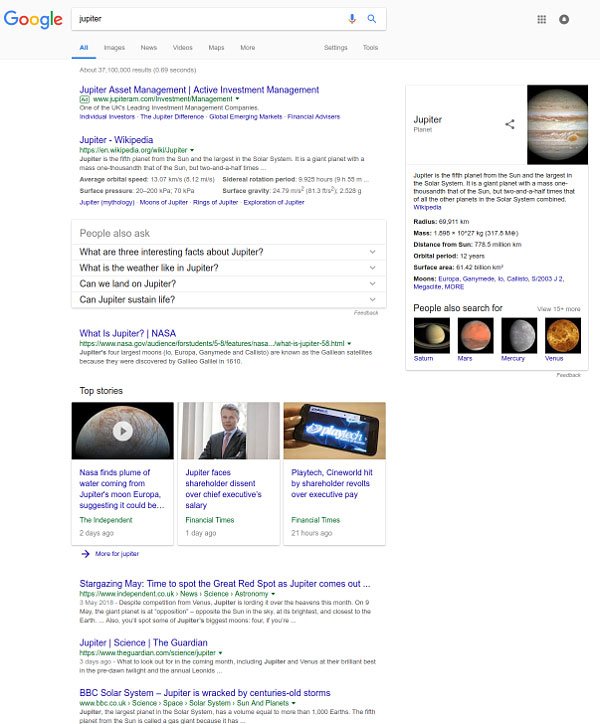
Illustration 5: Google SERP’s c.2018
It would help if you understood that semantic markup doesn’t necessarily improve ranking (though structured data markup is becoming increasingly essential), but it will improve visibility and provide specific answers to specific questions. When a search query elicits a particular entity, its appearance in search results will have a lot more detail or, in other words, will be content-rich with associated images, information, data, links all appearing, hooked into that entities web presence. Here’s a good article highlighting the benefits of engaging in Structured Data markup.
Click-Through Rate (“CTR”) is important, as well as dwell time on a page. Good quality content and excellent user experience are essential, and it will get your content and data appearing in those Rich Cards and Snippets. When users click on your listing and spend time on the page or share it and link to it, all that will be read by Google and solidify that page’s internet presence.
So, businesses themselves need to have a clear picture of who they are, what they do and why. Marketing experts are well acquainted with this sort of idea as it has solid ties to branding. The difference here is that every term can be linked to other WWW entities to disambiguate and make the message strong and clear.
Furthermore, the massive increase in voice searches and other non-PC queries makes allowing the essential data that is associated with an entity to be accessed by search engines even more important. Once Google has a verified and solid graph, it can use that to provide direct answers to questions.
Conclusion
Semantic markup is not yet obligatory, but it is fast becoming essential as the internet pitches towards “Things” and their presence as “Entities” with a place in the WWW. All this is aimed at helping the end-user by increasing accuracy, reliability, trust, and authority. It is essentially a return to the initial premise of creating content that is valuable and easy to find for the user. Yet, it is also a fundamental shift in the basis of connectivity and searches on the internet. The effects are only beginning to be felt as the data, context and meaning are sorted and analysed by the AI behind the big search engines. The transformation of the medium into entities connected by their meaning rather than arbitrary links brings the internet closer to the ideal as conceived by Tim Berners-Lee. Ultimately, looking at your digital presence with this in mind will help appreciate what you do, what you represent, and where you are as a business. And your visibility will be a signifier of how profound that appreciation and your ability to take part in the online conversation really are. Schema conveys many benefits, including the recent automatic eligibility for free shopping ads.
Useful Resources: